Generate labeled synthetic documents for OCR and document AI.
DocSet Generator is a Windows & Linux desktop generator for OCR training data, document AI evaluation, and extraction pipeline testing. 33 document types, controllable degradation, and ML-ready exports — COCO, LayoutLM, FUNSD, and DocVQA — with zero real PII.
See the output before you commit.
Download 50 real documents generated by DocSet Generator — across multiple types, clean and corrupted. No email required. No strings attached.
- PDF documents across 10+ types
- Clean and OCR-degraded versions
- Corrupt text layer examples
- Native formats included (.docx, .eml, .csv)
- 50 documents total, ready to inspect
// 50 documents · .zip archive · No signup required · .7z version
// Or generate your own right now — try the live browser demo →

Clean interface. No configuration required.
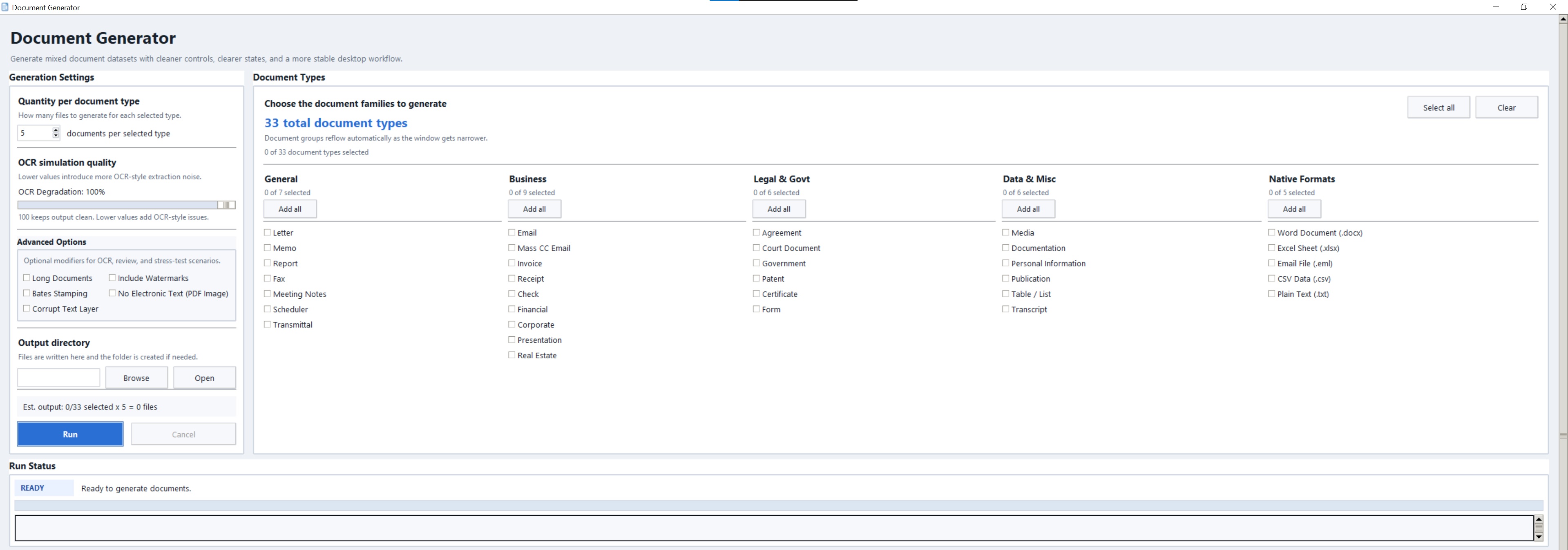
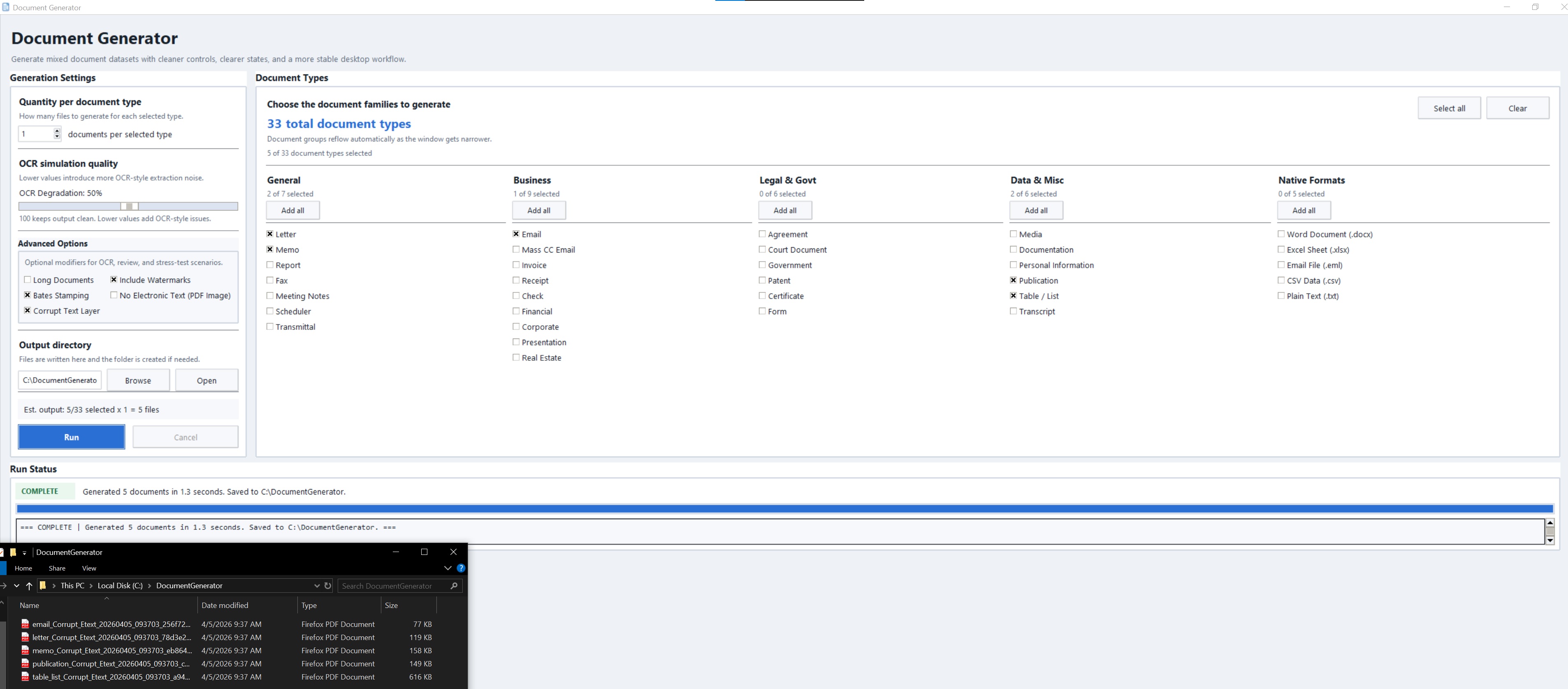
Fast enough to not be your bottleneck.
| Mode | Documents | Time | Workers | |
|---|---|---|---|---|
| Clean (100% quality) | 330 docs | 1.1s | 8 workers | |
| OCR Degraded (50%) | 330 docs | 11s | 8 workers | |
| Corrupt Text Layer | 330 docs | 11s | 4 workers | |
| Corrupt Text Layer (scale) | 3,300 docs | 104s | 4 workers |
// Worker count scales automatically based on your CPU and workload type. No configuration required.
ML-Ready Annotations
Export directly to COCO, LayoutLM, FUNSD, and DocVQA — word-detection boxes, token/label/normalized-box JSONL, question/answer/header roles with semantic links, and derived question-answer pairs. Train and fine-tune without writing a labeling pipeline.
Canonical Text + Geometry
A pre-render document model captures the exact text of every type — titles, paragraphs, list items, tables with merged-cell spans — before any corruption. Ships as a ground-truth text sidecar per document plus word → line → block boxes and key/value pairs.
Splits & Recipes
Deterministic, type-balanced train / validation / test splits with a configurable seed. Every run writes a replayable dataset_recipe.json, SHA-256 checksums, and a quality_report.json so datasets are reproducible and auditable.
OCR Corruption Slider
Control exactly how hard your model has to work. From clean ground truth to heavily degraded scans — continuous spectrum, not presets. Realistic character substitutions based on actual OCR failure patterns.
Corrupt Text Layer
Clean visual page, corrupted hidden text layer. Forces OCR fallback on tools that read embedded text directly. Tests the gap between what a document looks like and what an extractor actually reads.
Bates & Image-Only PDFs
Sequential Bates identifiers on every page for eDiscovery and legal AI pipelines, plus fully flattened image-only PDFs with no selectable text — a true visual-only extraction challenge, generated at scale.
Seeded & Byte-Identical
Seed a run and regenerate it exactly, down to byte-identical PDFs on the same platform. Derived per-document seeds, a fixed reference date, and normalized metadata make clean/degraded twin pairs and dataset replays deterministic.
Zero Real PII
All names, addresses, companies, SSNs, account numbers, and financial figures are synthetically generated — reserved .example domains, 555-01xx phones, invalid SSNs. Mathematically accurate but entirely fake.
Runs On-Prem
Windows and Linux desktop application. No internet required after install. No data sent to any server. Your training data stays on your machine — critical for regulated industries.
33 document types across every domain your pipeline will encounter.
General
- Letter
- Memo
- Report
- Fax
- Meeting Notes
- Scheduler
- Transmittal
Business
- Mass CC Email
- Invoice
- Receipt
- Check
- Financial
- Corporate
- Presentation
- Real Estate
Legal & Govt
- Agreement
- Court Document
- Government
- Patent
- Certificate
- Form
Data & Misc
- Media
- Documentation
- Personal Info
- Publication
- Table / List
- Transcript
Native Formats
- Word (.docx)
- Excel (.xlsx)
- Email (.eml)
- CSV (.csv)
- Plain Text (.txt)
From OCR test data to a full training dataset.
COCO · LayoutLM · FUNSD · DocVQA exports
Every run can emit ML-ready annotations: COCO word boxes in image pixels, LayoutLM token/label/normalized-box JSONL, FUNSD question/answer/header roles with links, and DocVQA Q&A pairs with word and page references. Drop it straight into training.
Canonical ground truth & rich annotations
A pre-render model captures the true text of all 33 types — headings, tables, merged-cell spans — before any corruption. Annotation schema 2.1 adds word → line → block geometry, table/row/cell records, entities, and key/value pairs, with a ground-truth text sidecar per document.
Reproducible datasets & recipes
Deterministic, type-balanced train/validation/test splits, a replayable dataset_recipe.json, byte-identical seeded PDFs, SHA-256 checksums, and a quality_report.json with per-type completeness metrics. Manifest schema 2.0 with built-in JSON Schema validation.
Now on Linux, too
Ships as a Linux AppImage and Flatpak alongside the Windows build, with high-fidelity LibreOffice rendering for native formats when available. Automatic parallel generation in the GUI, and coverage expanded from 33 tests to 104.
One price. No subscriptions. No usage limits.
Built for ML engineers and QA teams who need training data now, not after a procurement process. Buy once, generate as many documents as you need, keep every update.
Questions? Contact us at
hello@docsetgenerator.com
- Windows .exe + Linux AppImage & Flatpak
- 50-document sample pack included
- 33 document types across 5 categories
- COCO, LayoutLM, FUNSD & DocVQA exports
- Ground-truth text + word/line/block annotations
- Train / validation / test dataset splits
- OCR degradation slider + corrupt text layer
- Bates stamping, watermarks, image-only PDFs
- Seeded, reproducible generation with recipes
- Free updates — re-download anytime
- Runs fully offline — no data leaves machine
Or download the free sample first